
Todo lo que tu chatbot diga puede ser usado en tu contra.
Un tribunal regional alemán ha podido ser el que ha levantado un problema legal y económico en el centro de esta generación de inteligencia artificial.


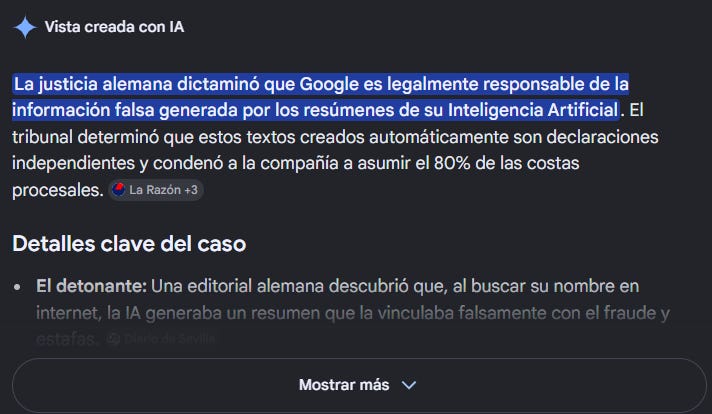
A finales de mayo, el Landgericht München I dictó medidas cautelares contra Google en un caso relacionado con la gran transformación del buscador: un resumen generado por inteligencia artificial. Un usuario tecleaba el nombre de una de las editoriales demandantes junto a «Betrugsmasche» (fraude, una palabra que sugería el sistema de autocompletado) y la «AI Overview» respondía que aquellas empresas eran conocidas por prácticas fraudulentas, que atraían a sus clientes a «trampas de suscripción» y que cambiaban de nombre con frecuencia: acusaciones que no figuraban en ninguna de las fuentes enlazadas que trataban concretamente sobre las editoriales y que estas pudieron refutar.
Lo interesante del caso es que el tribunal no trató ese texto como una lista de resultados ajenos ni a Google como un mero intermediario, sino como contenido propio de la empresa.
Durante décadas, los buscadores han disfrutado de una protección construida sobre la premisa de que el buscador no responde, solo descubre, ordena y enlaza: indexa contenido de terceros, lo cita con título y fragmento, y remite a la fuente. De modo que exigirle verificar todo lo que encuentra pondría en cuestión su propia existencia y su valor social. Lo que dice el tribunal es que no cabe trasladar esa protección a las AI Overviews, dado que estas no sólo enlazan y citan sino producen un texto nuevo que evalúa varias fuentes y las transforma en una respuesta «con sus propias palabras y según su propia estructura», que al usuario medio se le presenta como información directa de Google.
¿Qué cabe oponer en defensa de Google, que ha anunciado recurso alegando «errores específicos y acotados»? Por un lado, las empresas de IA apuntan a que el usuario ya sabe que el chatbot puede equivocarse y que es posible visitar las páginas enlazadas para comprobarlo. Pero para el tribunal la posibilidad de refutar después no exime de haber afirmado. Y sucede que casi nadie pincha en los enlaces si el resumen resuelve, aparentemente, el asunto consultado.
Pero creo que hay un argumento más que cabe discutir. La salida de un gran modelo de lenguaje está influida directamente por el prompt, que la dirige y diseña: si construyo una instrucción para que afirme una falsedad sobre alguien, lo fuerzo mediante un jailbreak hasta que la genere, ¿quién es el autor, el laboratorio creador del modelo o yo?
Una complicación más. En el caso de los modelos de IA de pesos abiertos, ¿quién es el «creador o modificador» responsable de lo que dice un Gemma, un Mistral o un Qwen ajustado por un tercero y corriendo en el portátil de alguien? ¿El laboratorio que liberó los pesos y ya no controla nada, el que hizo el fine-tuning, el que lo distribuyó, el que lo aloja, el que escribió el prompt?.
Los acuerdos sobre los que se ha ido construyendo la experiencia de internet se desdibujan. Las plataformas de contenidos y foros cada vez son cada vez más responsables de lo que publican los usuarios; quién habla frente a quién hospeda o quién distribuye lo que otros dicen queda cada vez más desdibujado por los sistemas de IA que crean textos, imágenes, vídeos. Ese cruce ya lo discutimos en 2023 en “La enorme dificultad de aceptar que el chatbot de inteligencia artificial inventa y se equivoca”.

Sin mucha jurisprudencia todavía, he ido a la búsqueda de casos similares. Tenemos el permisivo Walters v. OpenAI, en el que en 2025 un tribunal de Georgia dió la razón a OpenAI: ChatGPT había acusado en falso a un locutor de malversación, pero el sistema avisaba al usuario de posibles errores y el daño nunca llegó a difundirse. Por otro lado, tenemos el estricto Moffatt v. Air Canada, donde el chatbot se ofrecía en la web de la propia empresa y el tribunal respondió que el cliente no tiene por qué saber qué parte del sitio es fiable y cuál no: el bot es la empresa, y la empresa es responsable.
Es curioso porque en el primer caso el contexto de chatbot salva de la condena a la empresa de inteligencia artificial: no es comunicación pública, te avisa al empezar a usarlo de que se equivoca (algo sobre lo que tengo dudas como posible eximente) y es un caso de uso buscado por el usuario dentro de un contexto generalista. Parece más disculpable que el salto de Google de buscador a “respondedor”.
Empezamos así a examinar no tanto «¿quién escribió la frase?» como «¿quién diseñó y controla el sistema que la produjo?». Eugene Volokh planteó un enfoque práctico en «Large Libel Models?»: la responsabilidad podría activarse cuando la empresa recibe aviso de una falsedad concreta y no actúa, un régimen de aviso-y-bloqueo similar al conocimiento fehaciente en plataformas de que alguien ha subido algo ilegal. Esto probablemente generaría los mismos problemas y contradicciones: mucha gente pidiendo la retirada de afirmaciones que no son realmente erróneas, la empresa de IA erigiéndose en guardiana de la verdad y probablemente mucha autocensura y mucho control preventivo.
Con los buscadores encontramos fórmulas para que el bien social que producen sea protegido y su responsabilidad limitada. Con los sistemas de IA que indexan, agregan y responden generando nuevos textos necesitamos un nuevo acuerdo que dista de ser claro y evidente. Esta vez hablamos es una medida provisional, recurrida, y no deja de proceder de un tribunal regional alemán. Aún así, el problema de fondo afecta a toda la nueva web que está naciendo.
Relacionado:
Google en su etapa parasitaria

Con las resultonas infografías que se pueden hacer con Nano Banana Pro, Google ha encontrado una nueva vía viral para seguir popularizando sus aplicaciones de inteligencia artificial. Pero, al publicar este ejemplo creado dentro del magnífico NotebookLM, ha dejado entrever algo más que las capacidades visuales de su IA. Ha mostrado su nuevo posicionamie…
Ya veo en el horizonte una nueva DMCA...